5月14日,腾讯宣布旗下混元文生图大模型全面升级并对外开源。据悉,这是业内首个中文原生的DiT架构文生图开源模型。它支持中英文双语输入及理解,参数量15亿。目前,该大模型已在Hugging Face平台和Github上发布,包含模型权重、推理代码、模型算法等完整模型,可供企业与个人开发者免费商用。
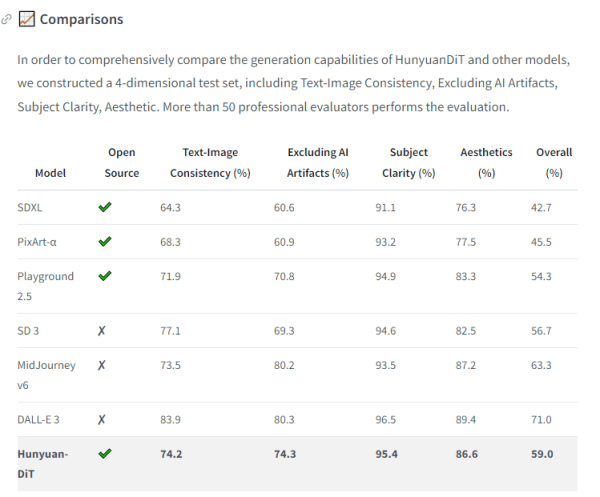
不同模型在图文一致性等方面的表现 图源Hugging Face
腾讯混元文生图负责人芦清林对观察者网表示,提升技术能力和更广泛的应用,是该大模型未来的两个方向。
"从技术能力的提升来说,如何让图片生成的速度更快,生成的质量更好,是我们永远都会追求的一个技术方向,它似乎是没有止境的。"芦清林表示,项目团队也希望该大模型,能在腾讯内外更广泛的业务场景应用起来。事实上,从去年开始,腾讯混元文生图就和腾讯的广告业务进行了一些协作。
"今年会跟社交业务,包括QQ、企业微信等很多业务场景做联动。跟他们合作做一些新的技术能力。"芦清林透露,同时,该大模型也会跟腾讯游戏做一些深入的技术合作,希望能够在美术场景中应用起来。包括QQ音乐等在内,也都是该大模型未来将会提供支撑的业务场景。
大模型的优异表现,往往离不开先进的技术架构。过去,视觉生成扩散模型主要基于U-Net架构,但随着参数量的提升,基于Transformer架构的扩散模型展现出了更好的扩展性,有助于进一步提升模型的生成质量及效率。升级后的腾讯混元文生图大模型采用了全新的DiT架构(即Diffusion With Transformer),这也是Sora和Stable Diffusion 3的同款架构和关键技术,它就是一种基于Transformer架构的扩散模型。
公开资料显示,在DiT架构的基础之上,腾讯混元文生图大模型还在算法层面优化了模型的长文本理解能力,能够支持最多256字符的内容输入,同时赋予其多轮生图和对话能力:在一张初始生成图片的基础上,用户通过自然语言描述,即可对其进行调整。
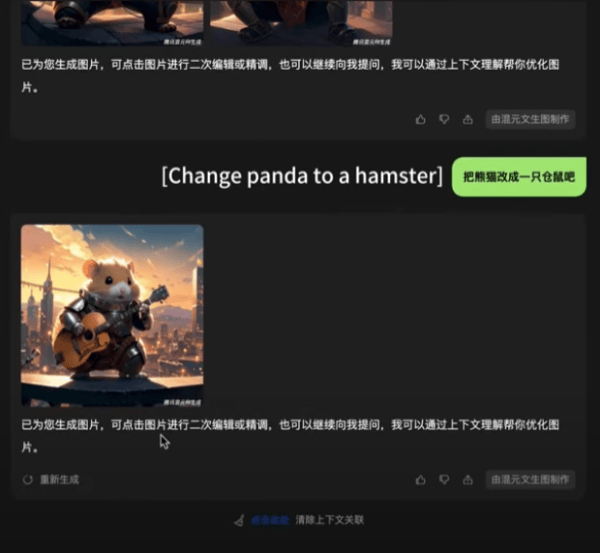
用户通过"对话",即可调整文生图的具体内容 测试截图
此外,"中文原生"也是腾讯混元文生图大模型的一大亮点,此前,像Stable Diffusion等主流开源模型核心数据集以英文为主,对中国的语言、美食、文化、习俗理解有限。作为首个中文原生的DiT模型,混元文生图具备中英文双语理解及生成能力,在古诗词、俚语、传统建筑、中华美食等中国元素的生成上表现出色。

混元文生图大模型的部分能力展示 图源Hugging Face